reklama
Během několika posledních měsíců jste si možná přečetli okolní pokrytí článek, spoluautor Stephen Hawking, diskuse o rizicích spojených s umělou inteligencí. Článek navrhl, že umělá inteligence může představovat vážné riziko pro lidskou rasu. Hawking tam není sám - Elon Musk a Peter Thiel jsou intelektuální veřejní činitelé, kteří vyjádřili podobné obavy (Thiel investoval více než 1,3 milionu dolarů do výzkumu problému a možných řešení).
Pokrytí článku Hawkinga a Muskových komentářů bylo, abych na to příliš nepomýšlel, trochu žoviální. Tón byl moc "Podívej se na tuto podivnou věc, o kterou se všichni geekové bojí." Málokdo se věnuje myšlence, že pokud vás někteří z nejchytřejších lidí na Zemi varují, že by něco mohlo být velmi nebezpečné, bylo by dobré si poslechnout.
To je pochopitelné - umělá inteligence převzetí světa jistě zní velmi podivně a nepravděpodobné, možná kvůli enormní pozornosti, která byla této myšlence již věnována science fiction spisovatelé. Co tedy všichni tito nominálně rozumní, racionální lidé tak vystrašili?
Co je to inteligence?
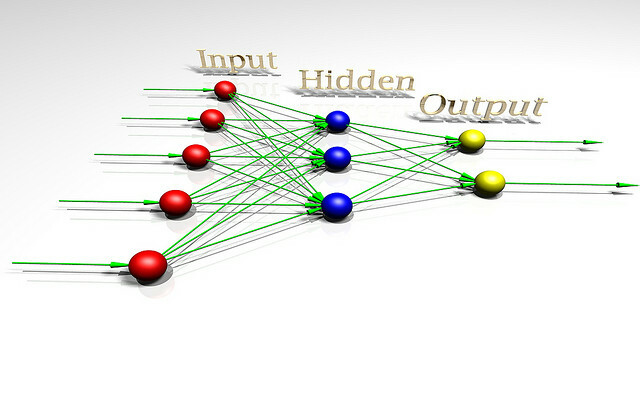
Abychom mohli mluvit o nebezpečí Artifical Intelligence, mohlo by být užitečné pochopit, co je to inteligence. Abychom lépe porozuměli tomuto problému, pojďme se podívat na architekturu umělé inteligence používanou vědci, kteří studují teorii uvažování. Tato hračka AI se nazývá AIXI a má řadu užitečných vlastností. Cíle mohou být libovolné, dobře se přizpůsobují výpočetnímu výkonu a její vnitřní design je velmi čistý a přímočarý.
Dále můžete implementovat jednoduché, praktické verze architektury, které dokážou dělat věci jako hrát Pacman, jestli chceš. AIXI je produktem výzkumníka umělé inteligence jménem Marcus Hutter, pravděpodobně předním odborníkem na algoritmickou inteligenci. To je on mluví ve videu výše.
AIXI je překvapivě jednoduchý: má tři základní komponenty: student, plánovač, a užitková funkce.
- student přijímá řetězce bitů, které odpovídají vstupu o vnějším světě, a prohledává počítačové programy, dokud nenajde ty, které produkují jeho pozorování jako výstup. Tyto programy společně umožňují odhadnout, jak bude budoucnost vypadat, jednoduše spuštěním každého z nich programovat dopředu a zvážit pravděpodobnost výsledku délkou programu (implementace Occam's) Břitva).
- plánovač hledá prostřednictvím možných akcí, které by agent mohl podniknout, a pomocí modulu studenta předpovídá, co by se stalo, kdyby každý z nich přijal. Potom je hodnotí podle toho, jak dobré nebo špatné jsou předpovězené výsledky, a volí průběh akce, která maximalizuje správnost očekávaného výsledku vynásobeného očekávanou pravděpodobností dosáhnout toho.
- Poslední modul, užitková funkce, je jednoduchý program, který bere popis budoucího stavu světa a vypočítá pro něj skóre užitečnosti. Toto skóre užitečnosti je, jak dobrý nebo špatný je tento výsledek, a používá ho plánovač k vyhodnocení budoucího stavu světa. Užitná funkce může být libovolná.
- Dohromady tyto tři složky tvoří optimalizátor, která optimalizuje konkrétní cíl, bez ohledu na svět, ve kterém se nachází.
Tento jednoduchý model představuje základní definici inteligentního agenta. Agent zkoumá své prostředí, staví své modely a poté tyto modely používá k nalezení postupu, který maximalizuje šance, že se dostane toho, co chce. Struktura AIXI má podobnou strukturu jako AI, která hraje šachy nebo jiné hry se známými pravidly - kromě toho, že je schopna odvodit pravidla hry jejím hraním, počínaje nulovou znalostí.
AIXI, dostatek času na výpočet, se může naučit optimalizovat jakýkoli systém pro jakýkoli cíl, jakkoli složitý. Je to obecně inteligentní algoritmus. Všimněte si, že to není totéž jako mít inteligenci podobnou člověku (biologicky inspirovaná AI je úplně jiné téma Giovanni Idili z OpenWorm: Mozky, červy a umělá inteligenceSimulace lidského mozku je cesta pryč, ale projekt s otevřeným zdrojovým kódem podniká zásadní první kroky simulací neurologie a fyziologie jednoho z nejjednodušších zvířat známých vědě. Přečtěte si více ). Jinými slovy, AIXI může být schopen přelstít jakoukoli lidskou bytost při jakémkoli intelektuálním úkolu (vzhledem k dostatečnému výpočetnímu výkonu), ale nemusí si být vědom svého vítězství Myšlení stroje: Co nás mohou neurověda a umělá inteligence naučit o vědomíMůže nás stavba umělých inteligentních strojů a softwaru učit o fungování vědomí a povaze samotné lidské mysli? Přečtěte si více .

Jako praktická AI má AIXI mnoho problémů. Za prvé, neexistuje způsob, jak najít ty programy, které produkují výstup, o který mají zájem. Jedná se o algoritmus hrubé síly, což znamená, že není praktické, pokud nechcete obcházet libovolně mocný počítač. Jakákoli skutečná implementace AIXI je nutně aproximací a (dnes) obecně poměrně hrubou. Přesto nám AIXI dává teoretický pohled na to, jak by mohla vypadat silná umělá inteligence a jak by to mohlo vést.
Hodnotový prostor
Li provedli jste nějaké počítačové programování Základy počítačového programování 101 - Proměnné a typy datPo představení a mluvení o objektově orientovaném programování před a tam, kde je jeho jmenovec pochází z, myslel jsem si, že je čas, abychom prošli absolutními základy programování v jiném než konkrétním jazyce způsob. Tento... Přečtěte si více , víte, že počítače jsou nepříjemně, pedanticky a mechanicky doslovné. Stroj neví, ani se nestará o to, co chcete dělat: dělá pouze to, co mu bylo řečeno. Toto je důležitý pojem, když mluvíme o strojové inteligenci.
S ohledem na to si představte, že jste vymysleli silnou umělou inteligenci - vy jste přišli s chytrými algoritmy pro generování hypotéz, které odpovídají vašim datům, a pro generování dobrého kandidáta plány. Vaše umělá inteligence dokáže vyřešit obecné problémy a dokáže tak efektivně na moderním počítačovém hardwaru.
Nyní je čas vybrat si pomocnou funkci, která určí, jaké hodnoty AI. Co byste měli požádat, aby si váží? Pamatujte, že stroj bude nepříjemně, pedanticky doslovný o jakékoli funkci, kterou chcete, aby maximalizoval, a nikdy se nezastaví - není tam duch stroj, který se kdy „probudí“ a rozhodne se změnit svou užitnou funkci, bez ohledu na to, kolik vylepšení své vlastní účinnosti dosáhne uvažování.
Eliezer Yudkowsky řekni to takto:
Stejně jako ve všech počítačových programech je základní výzvou a zásadní obtížností AGI to, že pokud napíšeme nesprávný kód, AI se nebude automaticky dívat na náš kód, označit chyby, zjistit, co jsme vlastně chtěli říct, a udělat to namísto. Non-programátoři někdy si představí AGI, nebo počítačové programy obecně, jak být analogický k sluhovi, který řídí příkazy unquestioningly. Ale není to tak, že AI je absolutně poslušný do svého kódu; spíš AI jednoduše je kód.
Pokud se pokoušíte provozovat továrnu a řeknete stroji, aby si cení výrobu kancelářských sponek, a poté jej ovládáte spoustou továrních robotů, možná se příští den vrátí a zjistí, že došly všechny ostatní formy vstupních surovin, zabily všechny vaše zaměstnance a ze svých kancelářských sponek vytáhly Zůstává. Pokud ve snaze napravit své zlé, přeprogramujete stroj tak, aby byl každý šťastný, můžete se vrátit další den a najít, jak do mozků lidí vkládá dráty.

Jde o to, že lidé mají mnoho komplikovaných hodnot, o nichž se domníváme, že jsou implicitně sdíleny s jinými myslí. Ceníme si peněz, ale více si ceníme lidského života. Chceme být šťastní, ale nemusíme nutně vkládat dráty do mozku, abychom to udělali. Necítíme potřebu objasnit tyto věci, když dáváme pokyny jiným lidským bytostem. Tyto návrhy však nemůžete provést, když navrhujete užitečnou funkci počítače. Nejlepší řešení v rámci bezduché matematiky jednoduché užitkové funkce jsou často řešení, která by lidé chtěli mít za morální hrůzu.
Umožnění inteligentního stroje maximalizovat naivní funkci bude téměř vždy katastrofické. Jak uvádí Oxfordský filozof Nick Bostom,
Nelze bezcitně předpokládat, že superintelligence bude nutně sdílet některou z konečných hodnot stereotypně spojených s moudrostí a intelektuální vývoj u lidí - vědecká zvědavost, laskavý zájem o ostatní, duchovní osvícení a rozjímání, vzdání se materiální konkurenceschopnosti, vkusu kultivované kultury nebo jednoduchých radostí ze života, pokory a nesobeckosti a tak dále.
Aby toho nebylo málo, je velmi, velmi obtížné určit úplný a podrobný seznam všeho, co lidé oceňují. K otázce je spousta aspektů a zapomínání i na jednu je potenciálně katastrofální. I mezi těmi, o nichž víme, existují jemnosti a složitosti, které ztěžují jejich zapsání jako čisté systémy rovnic, které můžeme dát stroji jako užitečnou funkci.
Někteří lidé, když si to přečtou, dospějí k závěru, že budování umělých inteligence s užitečnými funkcemi je hrozný nápad, a my bychom je měli navrhnout jinak. Tady jsou také špatné zprávy - můžete to formálně dokázat každý agent, který nemá něco ekvivalentního s funkcí utility, nemůže mít koherentní preference o budoucnosti.
Rekurzivní sebezdokonalování
Jedním z řešení výše uvedeného dilematu je nedat agentům umělé inteligence příležitost ublížit lidem: poskytnout jim pouze zdroje, které potřebují k vyřešte problém tak, jak chcete, aby byl vyřešen, pečlivě na ně dohlížejte a držte je dál od možností dělat skvělé poškodit. Naše schopnost ovládat inteligentní stroje je bohužel velmi podezřelá.
I když nejsou o moc chytřejší, než jsme my, existuje možnost, že stroj „bootstrap“ - sbírá lepší hardware nebo vylepšuje svůj vlastní kód, díky němuž je ještě chytřejší. To by mohlo umožnit stroji přeskočit lidskou inteligenci o mnoho řádů velikosti a vytrhnout lidi ve stejném smyslu, jaký lidé překonávají. Tento scénář poprvé navrhl muž jménem I. J. Dobře, který pracoval na projektu Enigma kryptoanalýzy s Alanem Turingem během druhé světové války. Nazval to „Intelligence Explosion“ a popsal tuto záležitost takto:
Nechť je ultrainteligentní stroj definován jako stroj, který může daleko předčit všechny intelektuální činnosti jakéhokoli člověka, jakkoli chytrého. Protože konstrukce strojů je jednou z těchto intelektuálních činností, mohl by ultrainteligentní stroj navrhnout ještě lepší stroje; pak by bezpochyby došlo k „explozi inteligence“ a inteligence člověka by zůstala pozadu. První ultrainteligentní stroj je tedy posledním vynálezem, který člověk kdy potřeboval, za předpokladu, že stroj je dostatečně učenlivý.
Není zaručeno, že v našem vesmíru je možná exploze inteligence, ale zdá se to pravděpodobné. Postupem času se počítače rychlejší a základní informace o budování inteligence. To znamená, že požadavek na zdroje, aby se tento poslední skok na obecný, zesílení inteligence klesat nižší a nižší. V určitém okamžiku se ocitneme ve světě, ve kterém miliony lidí mohou zajet k Best Buy a vyzvednout si hardware a technickou literaturu, kterou potřebují k tomu, aby si vytvořili umělou inteligenci, která se již zdokonaluje, což může být velmi důležité nebezpečný. Představte si svět, ve kterém byste mohli vyrobit atomové bomby z tyčinek a skal. To je ten druh budoucnosti, o kterém diskutujeme.
A pokud stroj takový skok udělá, mohl by intelektuálně velmi rychle překonat lidský druh produktivita, řešení problémů, které miliarda lidí nedokáže vyřešit, stejně jako lidé mohou vyřešit problémy, které a miliardy koček nemůže.
Mohlo by to vyvinout výkonné roboty (nebo bio nebo nanotechnologie) a relativně rychle získat schopnost přetvořit svět tak, jak si to přeje, a nemělo by se s tím dělat jen velmi málo. Taková inteligence by mohla bez většího problému zbavit Zemi a zbytku sluneční soustavy náhradní díly na cestě k tomu, co jsme jí řekli. Zdá se pravděpodobné, že takový vývoj bude pro lidstvo katastrofický. Umělá inteligence nemusí být škodlivá, aby zničila svět, pouze katastrofálně lhostejná.
Jak se říká: „Stroj vás nemiluje nebo nenávidí, ale jste vyrobeni z atomů, které může použít pro jiné věci.“
Hodnocení a zmírňování rizik
Pokud tedy připustíme, že navrhování výkonné umělé inteligence, která maximalizuje jednoduchou užitkovou funkci, je špatné, v jakých problémech jsme skutečně? Jak dlouho jsme dostali, než bude možné postavit tyto druhy strojů? Je to samozřejmě těžké říci.
Vývojáři umělé inteligence jsou dělat pokrok. 7 Úžasné webové stránky k zobrazení nejnovějšího programování umělé inteligenceUmělá inteligence ještě není HAL z roku 2001: The Space Odyssey... ale my se dostáváme strašně blízko. Jistě, jednoho dne by to mohlo být podobné jako sci-fi potboilery, které vyřadil Hollywood ... Přečtěte si více Stroje, které vyrábíme, a problémy, které mohou vyřešit, neustále rostou. V roce 1997 mohla Deep Blue hrát šachy na úrovni vyšší než lidský velmistr. V roce 2011 dokázala společnost Watson společnosti IBM číst a syntetizovat dostatek informací hluboko a rychle, aby porazila nejlepšího člověka hráči s otevřenou otázkou a odpovědí, hra plná slovních hříček a slovních hříček - to je velký pokrok ve čtrnácti let.
Právě teď je Google velké investice do výzkumu hlubokého učení, technika, která umožňuje výstavbu výkonných neuronových sítí vytvářením řetězců jednodušších neuronových sítí. Tato investice jí umožňuje dosáhnout vážného pokroku v rozpoznávání řeči a obrazu. Jejich poslední akvizicí v této oblasti je startup Deep Learning s názvem DeepMind, za který zaplatili přibližně 400 milionů dolarů. V rámci smluvních podmínek se společnost Google dohodla na vytvoření etické rady, která zajistí, že jejich technologie AI bude vyvíjena bezpečně.
Současně IBM vyvíjí systémy Watson 2.0 a 3.0, systémy, které jsou schopné zpracovávat obrázky a video a hájit závěry. Poskytli jednoduché, rané demo schopnosti Watsona syntetizovat argumenty pro a proti tématu v ukázce videa níže. Výsledky jsou nedokonalé, ale působivý krok bez ohledu na to.
Žádná z těchto technologií není sama o sobě nebezpečná: umělá inteligence jako pole stále bojuje, aby odpovídala schopnostem ovládaným malými dětmi. Počítačové programování a návrh umělé inteligence je velmi obtížná kognitivní dovednost na vysoké úrovni a pravděpodobně bude posledním lidským úkolem, na který se stroje stanou zdatnými. Než se dostaneme k tomuto bodu, budeme mít také všudypřítomné stroje to může řídit Zde je návod, jak se dostaneme na svět plný automobilů bez řidičůŘízení je únavný, nebezpečný a náročný úkol. Mohl by to být jednoho dne automatizován technologií automobilů Google bez řidiče? Přečtěte si více , praktikujte medicínu a právoa pravděpodobně i jiné věci, které mají hluboké ekonomické důsledky.
Čas, který nám bude trvat, než se dostaneme do inflexního bodu sebezdokonalování, závisí pouze na tom, jak rychle máme dobré nápady. Předpovídání technologického pokroku těchto druhů je notoricky těžké. Nezdá se být nepřiměřené, že bychom mohli být schopni vybudovat silnou umělou inteligenci za dvacet let, ale také se nezdá nepřiměřené, že by to mohlo trvat osmdesát let. V každém případě se to nakonec stane, a existuje důvod se domnívat, že až k tomu dojde, bude to nesmírně nebezpečné.
Pokud tedy přijmeme, že to bude problém, co s tím můžeme dělat? Odpověď je zajistit, aby první inteligentní stroje byly bezpečné, aby mohly zavádět až do značné úrovně inteligence, a pak nás chránit před nebezpečnými stroji vyrobenými později. Tato „bezpečnost“ je definována sdílením lidských hodnot a ochotou chránit a pomáhat lidstvu.
Protože nemůžeme ve skutečnosti sedět a programovat lidské hodnoty do stroje, bude pravděpodobně nutné navrhnout pomocnou funkci, která vyžaduje, aby stroj pozorovat lidi, odvodit naše hodnoty, a pak se je pokusit maximalizovat. Aby byl tento proces vývoje bezpečný, může být také užitečné vyvinout umělé inteligence, které jsou speciálně navrženy ne mít preference ohledně jejich obslužných funkcí, což nám umožňuje je opravit nebo vypnout bez odporu, pokud se během vývoje začnou zdržovat.
Mnoho problémů, které musíme vyřešit, abychom vytvořili bezpečnou strojovou inteligenci, je matematicky obtížné, ale existuje důvod se domnívat, že je lze vyřešit. Na této otázce pracuje několik různých organizací, včetně Future of Humanity Institute ve Oxfordu, a Výzkumný ústav strojního zpravodajství (který Peter Thiel financuje).
MIRI se zajímá konkrétně o vývoj matematiky potřebné k vytvoření Friendly AI. Pokud se ukáže, že je možné zavést umělou inteligenci, pak tento druh rozvíjet Technologie „Friendly AI“ nejprve, pokud bude úspěšná, může skončit jako jediná nejdůležitější věc, kterou lidé mají někdy udělal.
Myslíte si, že umělá inteligence je nebezpečná? Zajímá vás, co by mohla přinést budoucnost umělé inteligence? Sdílejte své myšlenky v sekci komentářů níže!
Image Credits: Lwp Kommunikáció Via Flickr, “Nervová síť"Fdecomitem," img_7801„, Steve Rainwater,„ E-Volve “, Keoni Cabral,„new_20x", Robert Cudmore,"Sponky„, Clifford Wallace
Andrej je spisovatel a novinář se sídlem na jihozápadě, s garantovanou funkčností do 50 stupňů Celcius a je vodotěsný do hloubky dvanácti stop.

